Czas wreszcie nadszedł by wszystkie usługi w mojej apce spiąć w jednym miejscu zarządzanym przez docker-compose. Skąd taka potrzeba? Powody są trzy. Mam już dość ręcznego uruchamiania bazy danych, serwera backendowego, frontendu, dodatkowych providerów etc. Wymaga to ode mnie wiedzy gdzie co się znajduje, jak to się odpala, jak trzeba konfigurować. Po za tym coś czuje, że wkrótce będę chciał to wszystko skalować przy użyciu Kubernetes^^. Nie przedłużając, dzisiejszym wpisem chciałbym się z Wami podzielić jak łatwo można puścić w kontener aplikacje napisaną w Vue z użyciem NuxtJs.
Po wielu godzinach spędzonych w internecie widzę, że królują dwa podejścia do tego problemu. Albo użyjemy Dockerfile, sami budując obraz z wykorzystaniem obrazu node albo użyjemy gotowca. Rozwiązanie ze stawianiem systemu i instalowaniem w nim node wydawało mi się zbyt karkołomne, więc w ogóle go nawet nie rozpatrywałem. Prostota zwyciężyła, postawiłem na gotowca.
W powyżym pliku docker-compose.yml tworze serwis frontend z gotowego obrazu node11. Wykonuje mapowanie między moim katalogiem web gdzie trzymam zawartość aplikacji frontendowej a katalogiem osiągalnym dla Node. Do kontenera dostarczam zmienne środowiskowe NUXT_HOST, NUXT_PORT, które rozpozna NuxtJs nasłuchując tym samym na porcie 3000, na wszystkich interfejsach. By całość zadziałała poprawnie musimy jeszcze utworzyć komendę ‘npm run docker‘, dodając ją do pliku package.json mniej więcej tak:
"scripts": {
"docker": "npm run dev",
(...)
}
Teraz pozostaje już w głównym katalogu wywołać docker-compose up. Pamiętajmy tylko, że jest to konfiguracja dla wersji deweloperskiej a nie produkcyjnej!
Przez to ciągłe przełanczanie się między językami programowania, często zdarza mi się zapomnieć składnie lub konstrukcje niektórych elementów. Dlatego dzisiaj prezentuje taką moją ściągawkę jeśli chodzi o podstawowe operacje na tablicach w JavaScript. Mam nadzieje, że to bedzie dla Was pomocne.
Asocjacje
Dla programistów PHP pewnym zaskoczeniem może być to, że JavaScript nie obsługuje tablic asocjacyjnych. Wszystkie indeksy muszą być typu liczbowego. Można to obejść stosując obiekty.
W przypadku tablic lepiej unikać porównania przez operator typeof – dla tablicy zwróci wartość object. Zamiast tego można skorzystać z Array.isArray(obj) lub instanceof. W przypadku tablicy właściwość length zwróci nam ilość jej elementów.
Operacje LIFO / FIFO
arr.push(element1, …, elementN) – dodaje jeden lub więcej elementów na koniec tablicy i zwraca jej nową długość. Metoda ta zmienia długość tablicy.
arr.pop() – usuwa ostatni element z tablicy zwracając go. Metoda ta zmienia długość tablicy.
arr.shift() – usuwa pierwszy element z tablicy i zwraca go. Metoda ta zmienia długość tablicy.
(Uwaga nie wszystkie przeglądarki) arr.find(callback[, thisArg]) – metoda find() zwraca pierwszy element tablicy, który spełnia warunek podanej funkcji testującej – wykonuje break.
Dzisiaj słów kilka na tema cech (ang. trait) czyli sposobu w PHP na wielodziedziczenie. Dzięki nim możemy użycie tych samych metod w wielu klasach. Zobaczmy poniższy przykład.
<?php
trait Cukier {
private $zawartosc = 0;
public function dosyp(int $ilosc)
{
$this->zawartosc += $ilosc;
}
}
trait Mleko {
private $zawartosc = 0;
public function dodaj(int $ilosc)
{
$this->zawartosc += $ilosc;
}
}
class Herbata {
use Cukier;
public function pobierzZawartosc(): int
{
return $this->zawartosc;
}
}
class Kawa {
use Cukier, Mleko;
}
$herbata = new Herbata();
$herbata->dosyp(2);
echo $herbata->pobierzZawartosc();
Definiujemy tu cechę Cukier, która będzie posiadać prywatną zmienną $zawartosc i metodę dosyp(). Cecha ta zostanie użyta w klasach Kawa i Herbata, czyli obie klasy uzyskają dostęp do metody i jej składowej. Co ciekawe dopuszcza się (gdy nie jest włączony tryb strict) powielenie składowej zarówno w innych cechach jak i klasach z nich korzystających (tak jak w tym przykładzie). Jak również możemy użyć niezdefiniowanej składowej pod warunkiem, że finalnie zostanie ona dostarczona przez inną cechę albo klasę. Oczywiście nic teraz nie stoi na przeszkodzie, aby cecha Cukier była adaptowana również do innych napojów, jak i by napój mógł korzystać z wielu różnych składników (Cukier, Mleko etc.) tak jak w przypadku Kawy.
Co jednak w przypadku konfliktu nazw? Załóżmy, że zarówna klasa jak i cecha, z której korzysta posiadają tą samą nazwę metody. W takim przypadku zostanie użyta metoda z klasy. Natomiast w sytuacji, w której konflikt nazw dotyczy cech (np. Cukier jak i Mleko posiadają wspólnie metodę dodaj()) uzyskamy fatal error. Możemy taką sytuacje naprawić przez określenie, która z metod ma zastosowanie w takim przypadku, tak jak poniżej.
class Kawa {
use Cukier, Mleko {
Cukier::dodaj insteadof Mleko;
Mleko::dodaj as dolej;
}
public function pobierzZawartosc(): int
{
return $this->zawartosc;
}
}
W powyższym przykładzie konflikt zostaje rozwiązany przez użycie metody z cechy Cukier, z kolei dla użycia metody dodaj() z cechy Mleka należy użyć wywołania spod aliasu dolej().
Nie mamy też przeszkody by zmieniać zakres widoczności metod w klasach używających danej cechy. Dla przykładu, mleka do kawy sobie nie dodamy 🙁
class Kawa {
use Mleko { dodaj as protected; }
public function pobierzZawartosc(): int
{
return $this->zawartosc;
}
}
$kawa = new Kawa();
$kawa->dodaj(2); //wygeneruje Uncaught Error: Call to protected method
echo $kawa->pobierzZawartosc();
Cechy mogą być również użyte do zgrupowania innych (wielu różnych) cech.
trait Dodatki {
use Cukier, Mleko;
}
class Kawa {
use Dodatki;
public function pobierzZawartosc(): int
{
return $this->zawartosc;
}
}
$kawa = new Kawa();
$kawa->dodaj(2);
echo $kawa->pobierzZawartosc();
Jeszcze inna ciekawa właściwość to stosowanie abstrakcji. Możemy zadeklarować daną metodę jako abstrakcyjną, gdzie klasa używająca cechy dostarczy jej definicje (analogicznie jak dla klas abstrakcyjnych). Zatem poprawiając dzisiejszy przykład, bardziej poprawnie byłoby zapisać go w następujący sposób.
<?php
trait Cukier {
protected $zawartosc = 0;
public function dodaj(int $ilosc)
{
$this->zawartosc += $ilosc;
}
abstract public function pobierzZawartosc(): int;
}
class Kawa {
use Cukier;
public function pobierzZawartosc(): int
{
return $this->zawartosc;
}
}
$kawa = new Kawa();
$kawa->dodaj(2);
echo $kawa->pobierzZawartosc();
Podsumowując myślę, że możliwości jakie dają nam cechy w języku PHP stanowią lepszą alternatywę do tradycyjnych dziedziczących po sobie klas. Oczywiście w przypadku gdy już na etapie projektowania wiemy, że ich metody mogą zostać wykorzystane w różnych częściach naszej aplikacji.
W dzisiejszym wpisie chce się z Wami podzielić moimi ostatnimi potyczkami z używaniem klas potomnych w Doctrinie gdy potrzebowałem zrobić bardziej zaawansowane zapytania w DQL.
Na pierwszy ogień przypadek operowania na właściwościach dostępnych tylko w klasie potomnej. Załóżmy, że mamy taką sytuacje – encje Word, przechowującej słówka do wyuczenia w ramach jakiegoś kursu internetowego. Mamy też jej klasę potomną DifficultWord, która posiada dodatkowe właściwości jak np. referencje do mema ułatwiającego zapamiętanie trudnego słowa. Encja Word jest również w relacji z uczestnikiem kursu. Gdybyśmy chcieli uzyskać informacje dla jakiego uczestnika przypisany jej konkretny mem z trudnym słówkiem to nie możemy operować tutaj encją Word (pułapka szczelinowa). W takim przypadku musimy złożyć zapytanie operując na jej klasie potomnej.
Całość sprowadza się tutaj do wykonania złączenia tabeli uczestników z ich trudnymi słówkami (join) i wyfiltrowanie właściwego mema (where).
Znacznie trudniejszy przypadek dotyczył operowaniem encją rodzica, ale w taki sposób jakby był klasą potomną. Trzymając się przytoczonego przykładu załóżmy, że chcemy pobrać listę słów, których nauczył się uczestnik kursu. Musimy tutaj pominąć trudne słowa. Jednocześnie pamiętamy, że przecież trudne słowa są podzbiorem słów jako takich. Stąd warunek taki jak poniżej się nie sprawdzi.
Po długich godzinach przeszukiwania stackoverflow znalazłem rozwiązanie działające z nowszymi wersjami Doctrina. Opiera się ono na wykorzystaniu dyskriminatora danej encji zamiast typu klasy (gdzie word jest właśnie nazwą dyskriminatora pożądanej encji, zgodnie z adnotacją DiscriminatorMap).
$qb->andWhere('w INSTANCE OF :type');
$qb->setParameter('type', 'word');
Kontynując wątek o wyjątkach w PHP chcę Wam przedstawić dwa nowe tricki, które ostatnio odkryłem. Nie są one jakieś rewolucyjne, ale pomagają mi szybciej i efektywniej zalogować wszelkie sytuacje krytyczne w aplikacji.
Od wersji PHP 7.1 istnieje możliwość przechwytywania wielu typów wyjątków w ramach tego samego bloku catch. Wszystko to za sprawą składni analogicznej do unii (“|”), tak jak poniżej.
<?php
class MyException extends Exception { }
class MyOtherException extends Exception { }
class Test {
public function testing() {
try {
throw new MyException();
} catch (MyException | MyOtherException $e) {
var_dump(get_class($e));
}
}
}
$foo = new Test;
$foo->testing();
?>
Źródło: https://www.php.net/manual/en/language.exceptions.php#example-294
Sporo czasu zajeło mi znalezienie jakiegoś łatwego i szybkiego sposobu do zalogowania wyjątku, tak by nie tracić podstawowych informacji do debugowania. Koniec końców postawiłem na prostotę przy użyciu metody toString() i kontekstu zgodnie z PSR3. Dzięki temu nie trzeba pisać boilerplate code, działa niezależenie od użytego w aplikacji logera i posiada informacje z komunikatem wyjątku, linią i plikiem jego wystąpienia. Dla przykładu.
try {
throw new \Exception('Some exception');
} catch (\Exception $ex) {
$this->logger->error(
'Text messsage',
[
'ex' => $ex,
]
);
}
Zalogowane jako
[2020-10-18 12:55:07] app.ERROR: Text messsage {"ex":"[object] (Exception(code: 0): Some exception at /home/dominik/application/src/Command/Auth.php:52)"} []
Witajcie po wakacyjnej przerwie. W dzisiejszym wpisie chcę się z Wami podzielić kilkoma moimi obserwacjami, które napotkałem ucząc się Nuxt.js i Vue przez właśnie wakacje.
Jak wygląda struktura plików w Nuxt.js?
Assets -> pliki takie jak SASS, LESS lub JavaScript.
Components -> reużywalne komponenty. np. navBar.vue.
Layout -> definicje wyglądu różnych elementów na stronie.
Middleware -> przechowuje funkcje, które mają się wykonać przed renderowaniem strony lub grupy stron.
Pages -> pliki vue opisujące działanie konkretnej strony.
Plugins -> kod JS, który ma się wykonać przed renderowaniem komponentów i stron.
To w jaki sposób będzie się odbywać komunikacja między przeglądarką a aplikacją zależy właśnie od tego mechanizmu. Jest to swego rodzaju nakładka na vue-router. Każda strona powinna znaleźć się w folderze pages i do niej automatycznie zostanie stworzony ruting. Jeśli plik nazywa się about.vue adres to naszadomena/about. By tworzyć ruting dynamiczny (z podaniem dodatkowych parametrów np. id) nazwa pliku musi zawierać prefiks “_“. Dla przykładu pages/users/_id.vue zostanie przetłumaczony na np. naszadomena/users/1. Z kolei z poziomu strony linki tworzymy analogicznie do <nuxt-link to=”Nazwa rutingu”>Przyjazna nazwa</nuxt-link>.
API
Pracując z Nuxt.js musimy pamiętać o różnicy między renderowaniem po stronie serwera a renderowaniem po stronie klienta. Gdy jesteśmy na poziomie serwera (Node.js) nie mamy dostępu do takich obiektów jak window czy document, które są dostępne po stronie przeglądarki. Zatem gdy jest taka konieczność, część logiki możemy przenieść na klienta wykorzystując w tym celu metodę beforeMount() lub mounted(), tak jak poniżej:
Ogólnie rzecz ujmując w momencie gdy przeglądarka wysyła żądanie do serwera Nuxt.js generuje HTML i wykonuje metody asyncData(), nuxtServerInit() i fetch(). Następnie przeglądarka odbiera taką stronę i Vue.js zaczyna być uruchomiony. Po czym użytkownik wędruje po stronach używając komponentu całkowicie bez uderzania do serwera.
Różnica między asyncData() i fetch()
Na koniec muszę wspomnieć o moich problemach ze zrozumieniem kiedy wywoływać metodę asyncData() a kiedy fetch() z API. Różnica jest dosyć subtelna, nie mniej istotna. Metoda asyncData() jest wykonywana po stronie serwera przed renderowaniem, fetch() podobnie przy czym nie ustawia obiektów po pobraniu i dlatego lepiej go stosować wraz z Vuex. Co ciekawe obie metody mogą być triggerowane gdy wymagają ich konkretne podstrony (tj. już po stronie klienta).
O zaletach korzystania z przestrzeni nazw w takich językach jak C++, Java czy PHP chyba nie trzeba nikogo przekonywać. Właściwie w dużych projektach, zwłaszcza w takich co silnie wykorzystują zewnętrzne biblioteki odpowiednia separacja kodu jest niezbędna. W tym artykule będę chciał przedstawić jak się sprawy mają w JavaScript historycznie jak i w dobie standardu ECMAScript 6 (ES6).
Dla osób przyzwyczajonych do technologii C++, Java czy PHP może być pewnym szokiem, że przestrzenie nazw jako takie w JavaScript nie istnieją. Zamiast tego wykorzystuje się tu koncepcje modułów, chociażby za sprawą ES6, który je ustandaryzował. Przedtem obowiązywały standard AMD z jego implementacją require.js dla rozwiązań po stronie klienta oraz CommonJS dla środowiska Node.Js. Był jeszcze standard UMD, który próbował połączyć obydwa te rozwiązania. To co stanowiło siłę tych technologii to ograniczenie modułów do jednego pliku, automatycznie załączanie modułów na podstawie ich wzajemnych zależności czy możliwość wczytywania poszczególnych modułów z różnych bibliotek bez ładowania całości.
require(["one", "two", "three"], function (one, two, three) { $('h1').html(three - one + two); }); });
gdzie na początku ustalamy ścieżkę do biblioteki jQuery, następnie deklarujemy moduł wstrzykując jQuery w zmiennej “$” oraz dociągamy kolejne moduły (one.js, two.js ,three.js).
A jak to wygląda obecnie, w dobie ECMAScript 6? Właściwie podobnie, moduły znajdują się w pliku js z tą różnicą, że jego wczytanie odbywa się przez słowo kluczowe import a deklaracja poprzez użycie export. Możemy eskportować zarówno funkcje, zmienne, stałe jaki klasy.
//plik pi.js export let PI = () => { return 3.14; };
//plik main.js import * as math from '~/static/pi.js' console.log(math.PI());
To o czym warto pamiętać w kontekście modułów z ES6 to, że:
domyślnie stosują tryb strict,
są one wczytywane asynchronicznie,
zmienne lokalne widoczne są jedynie w obrębie modułu,
są wywoływane tylko raz,
można je też zadeklarować poprzez znacznik “<script type=module>“.
Pewnym problemem może by wczytywanie dynamicznie modułów, powszechnie stosowanie rozwiązanie sprowadza się w takim przypadku do wykorzystania async/await
Dzisiaj słów kilka o dziedziczeniu w JavaScript. Tym wpisem chciałbym zainaugurować serią artykułów na temat różnych smaczków tego języka. Mam nadzieje, że to mi się uda a i że wy odkryjecie w tym coś interesującego dla was samych.
JS posiada dziedziczenie oparte o prototypach, stanowi to odmienne podejście niż to znane nam z języków takich jak np. Java czy PHP. Główna różnica to na brak klas (chociaż standard ECMAScript 6 wprowadził je do języka to i tak „pod spodem” mamy do czynienia z prototypami. Co to takiego te prototypy? Upraszczając, to zdolność obiektu do posiadania referencji __proto__, która przechowuje właściwości i metody będące klonowane (skopiowane) do klasy potomnej. Każdy obiekt w JavaScipt zawiera taką referencje, jest to tak zwany obiekt nadrzędny. W momencie gdy “klasa” potomna nie posiada żądanej metody, to silnik JS sprawdza obiekt rodzica a następnie obiekt nadrzędny w celu uzyskania danej metody. Poniżej prosty przykład, który to obrazuje.
// konstruktor
function Book(name) {
this.name = name || 'Eloquent JavaScript';
};
//dodawanie do prototypu
Book.prototype.getName = function () {
return this.name;
};
// utworzenie obiektu
var book = new Book();
// dziedziczenie
var technicalBook = Object.create(book); //Object.create istnieje od standardu ECMAScript 5
console.log(technicalBook.getName()); // Zwróci Eloquent JavaScript
Z kolei od ECMAScript 6 moglibyśmy to zapisać w taki sposób
class Book {
setName(name) {
this.name = name;
}
getName() {
return this.name;
}
}
class TechnicalBook extends Book {
}
let technicalBook = new TechnicalBook();
technicalBook.setName('Eloquent JavaScript');
console.log(technicalBook.getName()); // Zwróci Eloquent JavaScript
console.log(technicalBook.name); // Zwróci Eloquent JavaScript
Tyle na dzisiaj, a wy którą składnie bardziej preferujecie?
Dzisiejszy wpis będzie uzupełnieniem tematu, który poruszyłem jakiś czas temu tutaj. Spróbuję pokrótce opisać w jaki prosty sposób możemy ułożyć prostą dietę na redukcję. Zastrzegam przy tym, że prezentowane poniżej informacje są jedynie poglądowe. Jeśli jesteś zainteresowany ich wcieleniem w życie, to wcześniej skonsultuj się ze specjalistą.
Zanim przejdziemy do rozpisania konkretnego planu żywieniowego musimy odpowiedzieć sobie na kilka pytań. W pierwszej kolejności trzeba określić własny somatotyp (typ sylwetki). Pozwoli to nam lepiej dobrać zapotrzebowanie na makroskładniki. Wystarczy tu porównać prezentowane typy sylwetki z naszą. W tym przypadku precyzja nie jest zalecana bo w rzeczywistości spotyka się połączone w sobie cechy budowy różnych somatotypów. Nie mniej dla ektomorfików podstawą diety będą węglowodany, a dla endomorfikówtłuszcze. Kolejny krok to określenie BMR, tj. ilość kilokalorii, które potrzebuje nasz organizm, by utrzymać wszystkie funkcje życiowe (pomijając aktywność fizyczną). W internecie można spotkać wiele kalkulatorów pozwalających nam określić BMR, jednak za radą z książki “Najpierw wiedza potem rzeźba” ja postanowiłem uwzględnić również beztłuszczową masę ciała (LBM). W dużym uproszczeniu właściwe zapotrzebowanie kaloryczne (uwzględniające aktywność fizyczną) wyliczymy według wzoru:
LBM × 24 × A (w przypadku mężczyzn) LBM × 22 × A (w przypadku kobiet),
gdzie pod A podstawiamy 1,2 — znikoma aktywność fizyczna (np. praca za biurkiem). 1,3 — mała aktywność fizyczna (np. ćwiczenia raz w tygodniu). 1,4 — średnia aktywność fizyczna (np. dwa dość intensywne treningi w tygodniu). 1,5 — duża aktywność fizyczna (np. kilka cięższych treningów w tygodniu). 1,6 — bardzo duża aktywność fizyczna (minimum cztery cięż- kie treningi w tygodniu lub praca fizyczna).
Tematem dzisiejszego wpisu jest stworzenie diety na redukcje dlatego teraz zmniejszymy zapotrzebowanie kaloryczne o 10 % (zaleca się pozostać w przedziale 10 – 20 %). Przykładowo 2160 − 10% × 2160 = 1944 kcal – tyle będzie trzeba dostarczyć dziennie organizmowi energii.
Istotną rolę w każdej diecie stanowi odpowiednie zbilansowanie makroskładników. Zaliczamy do nich węglowodany, białka i tłuszcze. Najwięcej węglowodanów znajdziemy w owocach i warzywach, kaszach, ryżu, ziemniakach i batatach. Z kolei białek w rybach, jajkach, nabiale (jogurty, sery wiejskie), natomiast tłuszcze w mięsie (np. boczku), awokado, tłuszczach zwierzęcych (np. smalec, masło). Proporcje między makroskładnikami w naszej diecie określimy na podstawie typu sylwetki. Dla mezomorfika będzie to 40% węglowodanów, 30% białek, 30 % tłuszczy, a dla endomorfika 25% węglowodanów, 35% białek i 40 % tłuszczy.
Tak uzbrojeni w wiedzę możemy przejść do obliczenia właściwej gramatury posiłków. By to osiągnąć należy tak dobrać składniki naszej diety by nie przekroczyć naszego dziennego zapotrzebowania na kalorie a jednocześnie uwzględnić właściwy podział na makroskładniki. Pomocna w tym celu będzie ta tabelka.
Makroskładnik
Kcal
1g węglowodanów
4 kcal
1g białek
4 kcal
1g tłuszczów
9 kcal
W zależności od naszego typu sylwetki i dziennego zapotrzebowania na kalorie:
Węglowodany: 25% × 2000 kcal = 500 kcal (500 ÷ 4) tj. 125 g. Białka: 35% × 2000 kcal = 700 kcal tj. 175 g Tłuszcze: 40% × 2000 kcal = 800 kcal tj. 88 g.
Wszystko teraz sprowadza się do zbilansowania gramatury każdego posiłku w naszej diecie. Nie możemy przekroczyć wyliczonej wcześniej gramatury. By ułatwić jej ustalenie dla każdego posiłku w danym dniu, użyjemy wzoru:
Gramatura ÷ 100 × Makroskładnik na 100 g
Przykładowo ryż brązowy na 100 g posiada 23,9 g węglowodanów. Dla gramatury 50 g spożyjemy 12 g węglowodanów. Pozostaje tak dobrać posiłki i ich gramaturę by suma makroskładników zgadzała się z naszą dietą (polecam to zrobić w Ekselu).
Zastanówmy się jak mógłby wyglądać jeden przykładowy dzień. Na śniadanie jogurt naturalny (150 g) z musli, orzechami i suszonymi owocami (50 g). Drugie śniadanie to wołowina (100 g) z ryżem brązowym (30 g) podana z warzywami na patelnię. Na obiad risotto z kurczakiem (320 g). Podwieczorek sałatka z serem feta (125 g), a na kolacje kasza gryczana (50 g) z ogórkami kiszonymi. Mniam….
Reasumując, informacje tutaj zebrane są jedynie poglądowe. Jeśli zdecydujesz się na jakiś konkretny plan żywieniowy, to wcześniej skonsultuj to z dietetykiem. Nie ma też co traktować diety jako coś złego, najistotniejsze w tym wszystkim to czuć się z tym dobrze. Dlatego też nie ma sensu zanadto przejmować się tymi wszystkimi wyliczeniami i skrupulatnie się ich trzymać. Warto również przygotować sobie listę zakupów i posiadać potrzebne składniki “na zapas”, dzięki temu dużo łatwiej będzie nam wytrwać w naszych postanowieniach. Ja ze swojej strony kibicuje każdemu, kto dbając o własną sylwetkę sprawia, że jest bardziej efektywny 😉
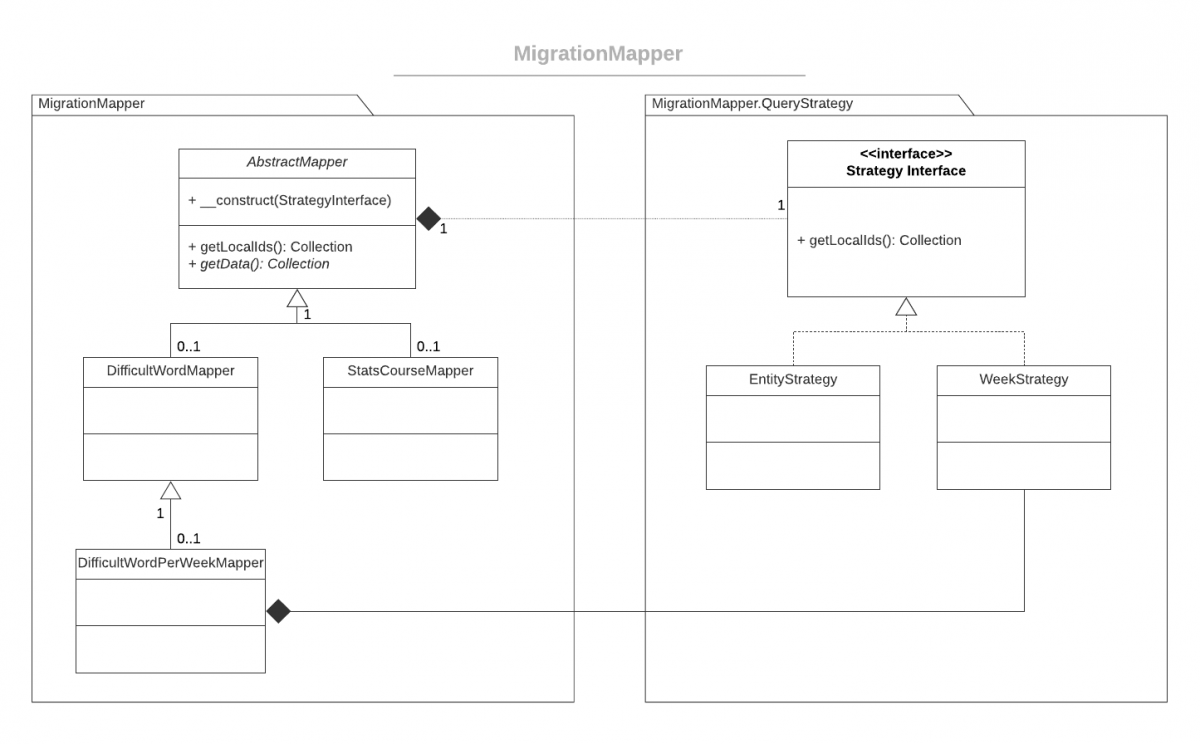
Jedna z wspaniałych rzeczy w IT to ta możliwość w kółko podchodzenia do starych problemów tworząc nowe rozwiązania(unifikacje) jednocześnie podważając dotychczasowe dogmaty. Właśnie w takim duchu będzie dzisiejszy wpis, czyli moja próba połączeniaantywzorca EAV (wyjaśniony niżej) z wzorcem Data Mapper. Moim celem jest utworzenie uniwersalnego mechanizmu do migracji danych z zewnętrznych serwisów. Opiszę to na podstawie aplikacji wspomagającej naukę języków obcych.
Na początku jednak kilka definicji użytych rozwiązań:
Data Mapper – “(…) to warstwa aplikacji odzielająca obiekty, którymi operujemy w pamięci, od bazy danych. Jej funkcją jest przekazywanie danych pomiędzy dwoma środowiskami przy jednoczesnym zachowaniu ich izolacji(…)“. M. Fowler.
Antywzorzec EAV (ang. Entity-Attribute-Value) – model danych, gdzie zarówno atrybuty jak ich wartości są zapisane w postaci rekordów, łamiąc tym samym pierwszą postać normalną.
Strategy – “Definiuje rodzinę wymiennych algorytmów i kapsułkuje je w postaci klas. Umożliwia wymienne stosowanie każdego z nich w trakcie działania aplikacji niezależnie od korzystających z nich użytkowników”. Gang of Four.
Iterator – “Zapewnia sekwencyjny dostęp do podobiektów zgrupowanych w większym obiekcie”. Gang of Four.
Dependency injection – “Wzorzec polegający na usuwaniu bezpośrednich zależności pomiędzy komponentami (…) Jest to realizacja paradygmatu odwrócenia sterowania“. M. Fowler
Repository – “Ogniwo łączące warstwę dziedziny oraz warstwę odwzorowania danych, wykorzystując przy tym interfejs przypominający kolekcję, który zapewnia dostęp do obiektów warstwy dziedziny“. M. Fowler.
Główną przesłanką za stosowaniem wzorca Data Mapper to wprowadzenie pewnej izolacji między bazą danych a aplikacją. Taka izolacja uprości implementacje z użyciem wzorców Lazy Load, Identity Map, Register czy Repository po stronie logiki dziedziny. Natomiast po stronie bazy danych użyty antywzorzec EAV zapewni sporą elastyczność dla dalszych rozszerzeń. Model danych składa się tutaj z trzech tabel:
Migration (tabela encji)
MigrationData (tabela atrybutów)
konkretna tabela (tabela wartości) np. w moim projekcie DifficultWord, StatsCourse
Założenie jest następujące. Wszystkie serwisy zdolne przeprowadzić migracje danych z zewnętrznego serwisu są przechowywane w tabeli Migration. Uzyskane dane trafiają do konkretnych tabel tutaj np. DifficultWord (tabela wartości). Natomiast informacje (metadane) o sposobie mapowania pobranych danych są zapisane jako atrybuty – w MigrationData. Zapisuje się tu również czas ostatniej migracji danych, tworząc niejako historię tych migracji. Tym samym prowadzi to do ich redundancji (co jak wspomniałem jest skutkiem złamania pierwszej postaci normalnej). Jest to jednak w tym przypadku pożądany efekt.
Przejdźmy teraz do samej aplikacji. W celu wydobycia danych np. z tabeli DifficultWord należy rozszerzyć klasę AbstractMapper o metodę zwracającą kolekcje obiektów konkretnej encji tutaj DifficultWord. Taka kolekcja musi wspierać iteracje (wzorzec iterator). Elementem opcjonalnym jest tutaj sposób / strategia pobierania identyfikatorów (kluczy do mapowania). Klasa pochodna może wymusić wstrzyknięcie innej strategi wyciągania kluczy. W moim przypadku taka potrzeba zaszła dla klasy DifficultWordPerWeekMapper, która wyciąga obiekty z bazy w odmienny sposób niż domyślna strategia, grupując je względem tygodni. Poniżej przykład.
/**
* @return Collection
* @throws DBALException
*/
public function getLocalIds(): Collection
{
$sql = <<<SQL
SELECT numberWeek, d.local_id as localId
FROM migration as m
LEFT JOIN migration_data as d ON m.id = d.migration_id,
(
SELECT strftime('%W', m.create_at) as numberWeek, max(m.id)
as migrationId
FROM migration as m
WHERE status = 1 AND `type` = :type
GROUP BY numberWeek
)
WHERE m.id = migrationId
SQL;
/** @var Statement $query */
$query = $this->doctrine->getConnection()->prepare($sql);
$query->bindParam(':type', $this->type);
$query->execute();
return new ArrayCollection($query->fetchAll());
}
Gdy już posiadamy identyfikatory właściwych rekordów do pobrania, konkretna realizacja klasy AbstractMapper dostarcza logikę pobrania danych w metodzie getData() używając w tym celu repozytorium. Przykład dla DifficultWord poniżej.
public function getData(): Collection
{
$difficultWordIds = $this->getLocalIds()->getValues();
return new ArrayCollection($this->difficultWordRepository
->findBy([
'id' => $difficultWordIds
]));
}
Prezentowane rozwiązanie spełnia wszystkie postawione przeze mnie kryteria. Kod i jego architektura jest prosta, czytelna i łatwo rozszerzalna. Dla kolejnych bytów w aplikacji wystarczy dopisać odpowiedni maper, a w skrajnych sytuacjach również strategię pobierania kluczy. Całość całkiem dobrze współgra z wspomnianymi wzorcami Lazy Load, Identity Map, Register, Repository czy Iterator. Jednakże takie rozwiązanie wykorzystujące antywzorzec EAV może w przyszłości stworzyć wiele problemów: “(…) Musimy jednak pamiętać, że doświadczeni konsultanci zajmujący się bazami danych konsekwentnie powtarzają, że systemy stosujące ten antywzorzec (tutaj EAV) tracą sprawność już w ciągu roku od wdrożenia.” Bill Karwin, Antywzorce języka SQL. Na jeszcze inną kwestie zwraca uwagę Fowler opisując konsekwencje używania Data Mapper a tyczy się ona problemów wydajnościowych. Data Mapper niekiedy by wyciągnąć jeden obiekt musi kilkukrotnie odpytać bazę danych. W najprostszym przypadku aplikacja dla każdego żądania generuje po dwa zapytania do bazy danych. Przy czym liczba kolejnych żądań może się zwiększyć z czasem. Wydaje się jednak, że dla prostych projektów bez zbytnio skomplikowanej logiki dziedziny, taki sposób obsługi danych podlegających migracji powinien wystarczyć.