
Jedna z wspaniałych rzeczy w IT to ta możliwość w kółko podchodzenia do starych problemów tworząc nowe rozwiązania(unifikacje) jednocześnie podważając dotychczasowe dogmaty. Właśnie w takim duchu będzie dzisiejszy wpis, czyli moja próba połączenia antywzorca EAV (wyjaśniony niżej) z wzorcem Data Mapper. Moim celem jest utworzenie uniwersalnego mechanizmu do migracji danych z zewnętrznych serwisów. Opiszę to na podstawie aplikacji wspomagającej naukę języków obcych.
Na początku jednak kilka definicji użytych rozwiązań:
- Data Mapper – “(…) to warstwa aplikacji odzielająca obiekty, którymi operujemy w pamięci, od bazy danych. Jej funkcją jest przekazywanie danych pomiędzy dwoma środowiskami przy jednoczesnym zachowaniu ich izolacji(…)“. M. Fowler.
- Antywzorzec EAV (ang. Entity-Attribute-Value) – model danych, gdzie zarówno atrybuty jak ich wartości są zapisane w postaci rekordów, łamiąc tym samym pierwszą postać normalną.
- Strategy – “Definiuje rodzinę wymiennych algorytmów i kapsułkuje je w postaci klas. Umożliwia wymienne stosowanie każdego z nich w trakcie działania aplikacji niezależnie od korzystających z nich użytkowników”. Gang of Four.
- Iterator – “Zapewnia sekwencyjny dostęp do podobiektów zgrupowanych w większym obiekcie”. Gang of Four.
- Dependency injection – “Wzorzec polegający na usuwaniu bezpośrednich zależności pomiędzy komponentami (…) Jest to realizacja paradygmatu odwrócenia sterowania“. M. Fowler
- Repository – “Ogniwo łączące warstwę dziedziny oraz warstwę odwzorowania danych, wykorzystując przy tym interfejs przypominający kolekcję, który zapewnia dostęp do obiektów warstwy dziedziny“. M. Fowler.
Główną przesłanką za stosowaniem wzorca Data Mapper to wprowadzenie pewnej izolacji między bazą danych a aplikacją. Taka izolacja uprości implementacje z użyciem wzorców Lazy Load, Identity Map, Register czy Repository po stronie logiki dziedziny. Natomiast po stronie bazy danych użyty antywzorzec EAV zapewni sporą elastyczność dla dalszych rozszerzeń. Model danych składa się tutaj z trzech tabel:
- Migration (tabela encji)
- MigrationData (tabela atrybutów)
- konkretna tabela (tabela wartości) np. w moim projekcie DifficultWord, StatsCourse
Założenie jest następujące. Wszystkie serwisy zdolne przeprowadzić migracje danych z zewnętrznego serwisu są przechowywane w tabeli Migration. Uzyskane dane trafiają do konkretnych tabel tutaj np. DifficultWord (tabela wartości). Natomiast informacje (metadane) o sposobie mapowania pobranych danych są zapisane jako atrybuty – w MigrationData. Zapisuje się tu również czas ostatniej migracji danych, tworząc niejako historię tych migracji. Tym samym prowadzi to do ich redundancji (co jak wspomniałem jest skutkiem złamania pierwszej postaci normalnej). Jest to jednak w tym przypadku pożądany efekt.
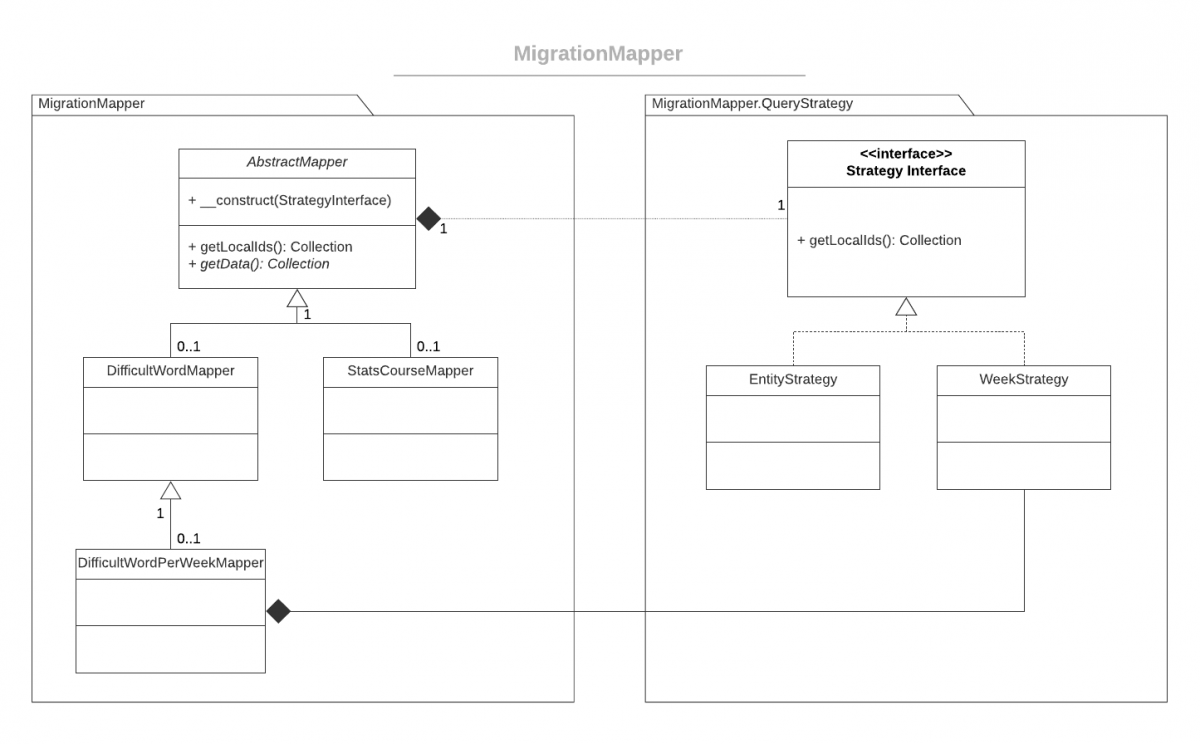
Przejdźmy teraz do samej aplikacji. W celu wydobycia danych np. z tabeli DifficultWord należy rozszerzyć klasę AbstractMapper o metodę zwracającą kolekcje obiektów konkretnej encji tutaj DifficultWord. Taka kolekcja musi wspierać iteracje (wzorzec iterator). Elementem opcjonalnym jest tutaj sposób / strategia pobierania identyfikatorów (kluczy do mapowania). Klasa pochodna może wymusić wstrzyknięcie innej strategi wyciągania kluczy. W moim przypadku taka potrzeba zaszła dla klasy DifficultWordPerWeekMapper, która wyciąga obiekty z bazy w odmienny sposób niż domyślna strategia, grupując je względem tygodni. Poniżej przykład.
/**
* @return Collection
* @throws DBALException
*/
public function getLocalIds(): Collection
{
$sql = <<<SQL
SELECT numberWeek, d.local_id as localId
FROM migration as m
LEFT JOIN migration_data as d ON m.id = d.migration_id,
(
SELECT strftime('%W', m.create_at) as numberWeek, max(m.id)
as migrationId
FROM migration as m
WHERE status = 1 AND `type` = :type
GROUP BY numberWeek
)
WHERE m.id = migrationId
SQL;
/** @var Statement $query */
$query = $this->doctrine->getConnection()->prepare($sql);
$query->bindParam(':type', $this->type);
$query->execute();
return new ArrayCollection($query->fetchAll());
}Gdy już posiadamy identyfikatory właściwych rekordów do pobrania, konkretna realizacja klasy AbstractMapper dostarcza logikę pobrania danych w metodzie getData() używając w tym celu repozytorium. Przykład dla DifficultWord poniżej.
public function getData(): Collection
{
$difficultWordIds = $this->getLocalIds()->getValues();
return new ArrayCollection($this->difficultWordRepository
->findBy([
'id' => $difficultWordIds
]));
}Prezentowane rozwiązanie spełnia wszystkie postawione przeze mnie kryteria. Kod i jego architektura jest prosta, czytelna i łatwo rozszerzalna. Dla kolejnych bytów w aplikacji wystarczy dopisać odpowiedni maper, a w skrajnych sytuacjach również strategię pobierania kluczy. Całość całkiem dobrze współgra z wspomnianymi wzorcami Lazy Load, Identity Map, Register, Repository czy Iterator. Jednakże takie rozwiązanie wykorzystujące antywzorzec EAV może w przyszłości stworzyć wiele problemów: “(…) Musimy jednak pamiętać, że doświadczeni konsultanci zajmujący się bazami danych konsekwentnie powtarzają, że systemy stosujące ten antywzorzec (tutaj EAV) tracą sprawność już w ciągu roku od wdrożenia.” Bill Karwin, Antywzorce języka SQL. Na jeszcze inną kwestie zwraca uwagę Fowler opisując konsekwencje używania Data Mapper a tyczy się ona problemów wydajnościowych. Data Mapper niekiedy by wyciągnąć jeden obiekt musi kilkukrotnie odpytać bazę danych. W najprostszym przypadku aplikacja dla każdego żądania generuje po dwa zapytania do bazy danych. Przy czym liczba kolejnych żądań może się zwiększyć z czasem. Wydaje się jednak, że dla prostych projektów bez zbytnio skomplikowanej logiki dziedziny, taki sposób obsługi danych podlegających migracji powinien wystarczyć.