
O zaletach stosowania i czym w ogóle jest Continuous integration(CI) nie będę się w tym wpisie rozwodził. Wydaje się, że tyle już zostało powiedziane w tym temacie, że to wszystko staje się aż do bólu oczywiste w samej teorii. Dlatego dzisiejszy wpis chce by miał bardziej praktyczne podejście do tego. Od dłuższego czasu szukam jakiejś w miarę sensownej konfiguracji Jenkinsa pod projekty pisane w PHP. Niestety od momentu wprowadzenia Pipeline, wiele rozszerzeń dedykowanych pod PHP po prostu z tym nie współgra. Poniżej prezentuje co udało mi się ustalić i jak to wygląda w moim projekcie gdzie na pokładzie jest Symfony4 z testami pisanym w PHPUnit. Jednakże dla osób niezaznajomionych lub wciąż głodnych dodatkowych informacji, z całego serca mogę polecić książkę Continuous Integration: Improving Software Quality and Reducing Risk.
Na świeżej instalacji Jenkinsa 2.176.1 musiałem dodatkowo zainstalować następujące pluginy:
- PHP Built-in Web Server
- HTML Publisher – umożliwia publikowanie raportu z pokrycia kodu testami
- Clover – ustawia zachowania build’a na podstawie wyników z pokrycia kodu
- Clover PHP – PHP’owy wrapper na Clover
- Javadoc – prezentuje dokumentacje z phpdoc
- Static Analysis Utilities
- Checkstyle – przechwytuje raport z phpcs
- PMD – przechwytuje raport z phpmd
- DRY – przechwytuje raport z phpcpd
- Bitbucket Plugin – umożliwia przechwycenie webhook’a z Bitbucket (więcej o tym w dalszej części wpisu)
Poniżej Jenkinsfile
#!/usr/bin/env groovy
node {
stage('Get code from SCM') {
checkout(
[$class: 'GitSCM', branches: [[name: 'master']],
doGenerateSubmoduleConfigurations: false,
extensions: [],
submoduleCfg: [],
userRemoteConfigs: [[url: 'git@adresrDoRepo.git', credentialsId: 'user']]]
)
}
stage('Prepare') {
sh 'composer install'
sh 'bin/console assets:install'
sh 'bin/console cache:clear'
sh 'bin/console doctrine:database:create'
sh 'bin/console doctrine:migrations:migrate --no-interaction'
}
stage('PHP Syntax check') {
sh 'vendor/bin/parallel-lint --exclude vendor/ --exclude ./bin .'
}
stage('Symfony Lint') {
sh 'bin/console lint:yaml src'
sh 'bin/console lint:yaml tests'
sh 'bin/console lint:twig src'
sh 'bin/console lint:twig tests'
}
stage("PHPUnit") {
sh 'bin/phpunit --coverage-html build/coverage --coverage-clover build/coverage/index.xml'
}
stage("Publish Coverage") {
publishHTML (target: [
allowMissing: false,
alwaysLinkToLastBuild: false,
keepAll: true,
reportDir: 'build/coverage',
reportFiles: 'index.html',
reportName: "Coverage Report"
])
}
stage("Publish Clover") {
step([
$class: 'CloverPublisher',
cloverReportDir: 'build/coverage',
cloverReportFileName: 'index.xml',
healthyTarget: [methodCoverage: 70, conditionalCoverage: 80, statementCoverage: 80], // optional, default is: method=70, conditional=80, statement=80
unhealthyTarget: [methodCoverage: 50, conditionalCoverage: 50, statementCoverage: 50], // optional, default is none
failingTarget: [methodCoverage: 0, conditionalCoverage: 0, statementCoverage: 0] // optional, default is none
])
}
stage('Checkstyle Report') {
sh 'vendor/bin/phpcs --report=checkstyle --report-file=build/logs/checkstyle.xml --standard=phpcs.xml --extensions=php,inc -wp || exit 0'
checkstyle pattern: 'build/logs/checkstyle.xml'
}
stage('Mess Detection Report') {
sh 'vendor/bin/phpmd . xml phpmd.xml --reportfile build/logs/pmd.xml || exit 0'
pmd canRunOnFailed: true, pattern: 'build/logs/pmd.xml'
}
stage('CPD Report') {
sh 'vendor/bin/phpcpd --log-pmd build/logs/pmd-cpd.xml --exclude bin --exclude vendor --exclude src/Migrations --exclude var . --progress || exit 0'
dry canRunOnFailed: true, pattern: 'build/logs/pmd-cpd.xml'
}
stage('Lines of Code') {
sh ' vendor/bin/phploc --count-tests --log-csv build/logs/phploc.csv --log-xml build/logs/phploc.xml . --exclude vendor --exclude src/Migrations --exclude var .'
}
stage('Software metrics') {
sh 'vendor/bin/pdepend --jdepend-xml=build/logs/jdepend.xml --jdepend-chart=build/dependencies.svg --overview-pyramid=build/overview-pyramid.svg --ignore=vendor,var,bin,build .'
}
stage('Generate documentation') {
sh 'vendor/bin/phpdox -f phpdox.xml'
}
stage('Publish Documentation') {
publishHTML (target: [
allowMissing: false,
alwaysLinkToLastBuild: false,
keepAll: true,
reportDir: 'docs/html',
reportFiles: 'index.xhtml',
reportName: "PHPDox Documentation"
])
}
}Wycinek z composer.json
"require-dev": {
"jakub-onderka/php-parallel-lint": "^1.0",
"pdepend/pdepend": "@stable",
"phploc/phploc": "^5.0",
"phpmd/phpmd": "@stable",
"sebastian/phpcpd": "^4.1",
"squizlabs/php_codesniffer": "*",
"symfony/debug-pack": "*",
"symfony/maker-bundle": "^1.0",
"symfony/phpunit-bridge": "^5.0",
"symfony/profiler-pack": "*",
"symfony/test-pack": "*",
"symfony/web-server-bundle": "4.3.*",
"theseer/phpdox": "^0.12.0"
},
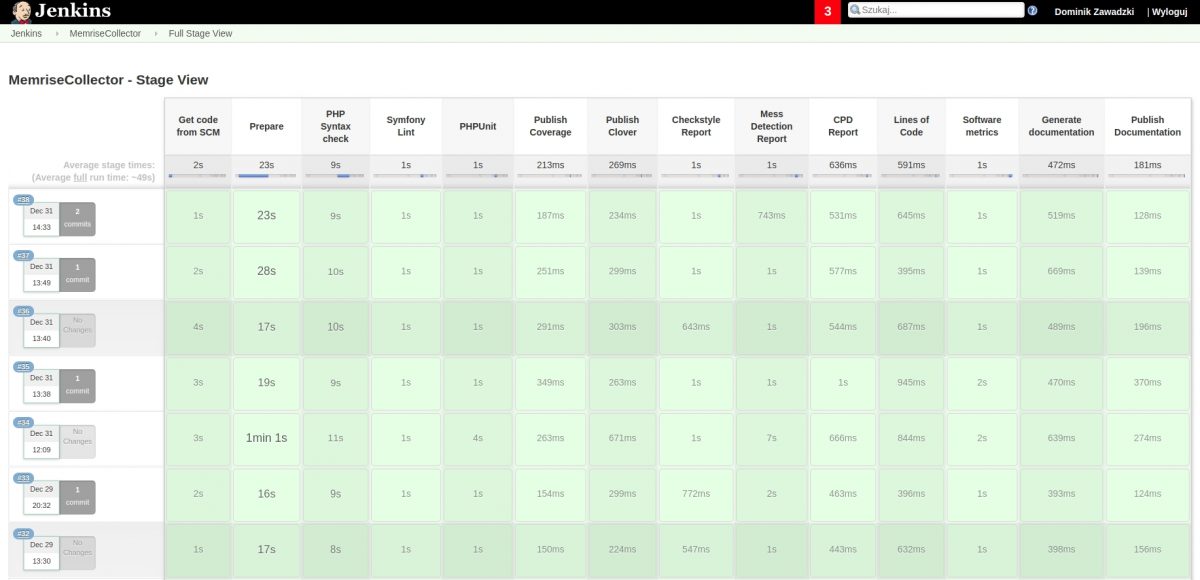
A tak wygląda mój dashboard po tych buildach
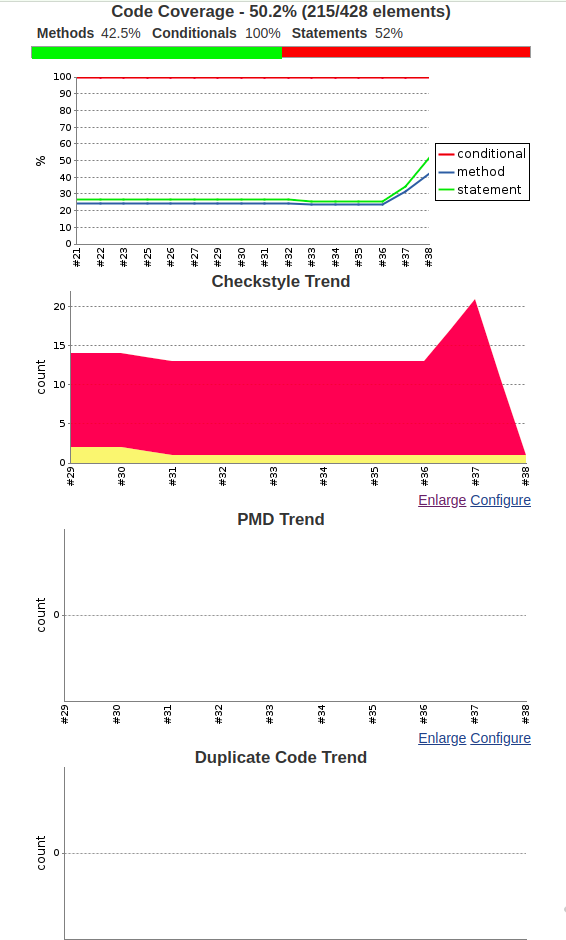
W trakcie implementacji natknąłem się na dwa problemy. Pierwszy dotyczył ustawienia w Jenkinsie Credentials dla wygenerowanego klucza z dostępem do repozytorium Git. Pamiętajmy, że trzeba taki klucz publiczny utworzyć i zapisać w ustawieniach Jenkinsa – Credentials. Następnie w pliku Jenkinsfile w parametrze userRemoteConfigs należy ustawić credentialsId z identyfikatorem podanym w zakładce Credentials. Ciekawą opcją w przypadku używania akurat Bitbucket jest możliwość wygenerowania klucza z dostępem tylko do odczytu repozytorium. Zdecydowanie polecam tą opcję dla przyznania dostępu dla Jenkinsa. Inną problematyczną kwestią z jaką się spotkałem było przechwycenie webhooka z Bitbucket. Albo występował problem z uprawnieniami, albo serwer Jenkinsa klasyfikował żądanie jako nieprawidłowe. Gdy się z tym uporałem okazało się, że build dla gałęzi master idzie także wtedy gdy zostanie zrobiony push do innego brancha. Koszmar! Rozwiązanie, użyć pluginu bitbucket w Jenkinsie.
A Wy jaką macie konfiguracje ? 😉